Mapas de calor y Algoritmo de Centro de Gravedad utilizando Python
Análisis preliminar y alternativas de localización
Ya en artículos anteriores hemos abordado el uso de tecnología como herramienta que permita desarrollar problemas de análisis preliminar y localización de instalaciones, con el objetivo de incrementar el nivel de aplicabilidad de estas herramientas, utilizando algunos entornos de programación, algunos sistemas de información geográfica, librerías de geocodificación; etc., que nos facilitan la adopción de soluciones basadas en entornos reales.
Algunos de los artículos que hemos desarrollado al respecto son:
En estos artículos mencionamos que los mapas de calor aplicados a la localización de instalaciones, son capas de visualización que no nos proporcionan como resultado una localización específica; sí nos proporcionan una visión de densidad basada en un factor de ponderación establecido (Peso). Sin embargo, al utilizar mapas de calor en entornos como por ejemplo Python, podemos integrar a esta herramienta, un método heurístico que nos proporcione una localización específica, como por ejemplo el Centro de Gravedad.
El objetivo de este artículo será el de utilizar mapas de calor y el algoritmo de Centro de gravedad de manera simultánea a través de Python; como herramienta de análisis preliminar y de localización de una instalación.
En el desarrollo de este ejercicio emplearemos:
- Colaboratory: Este es un entorno de programación y ejecución virtual de Python desarrollado por Google. Nos permitirá no tener la necesidad de realizar ninguna instalación en nuestros equipos. Todo lo que desarrollemos lo ejecutaremos en un cuaderno virtual.
- Python: Este será el lenguaje de programación que vamos a utilizar, y advertimos: No es necesario tener conocimientos previos, y el objetivo del artículo no es convertirnos en programadores expertos. Utilizaremos fragmentos de códigos, librerías disponibles, y explicaremos lo necesario para configurar nuestro desarrollo de acuerdo a los objetivos específicos de nuestros modelos.
- Geopy: Las librerías son a Python, lo que las apps son a un teléfono celular. Esta es quizá una de las características más a tractivas de este lenguaje: Casi que existe una librería para cada necesidad. En este caso, Geopy, es una librería que nos permitirá geocodificar un conjunto de ubicaciones. Es decir, a partir de un listado de ciudades o direcciones, poder obtener sus coordenadas de latitud y longitud que nos permitan georeferenciar dichas ubicaciones.
- Statistics: Esta es una librería con un conjunto de herramientas estadísticas que nos permitirán hallar algunas medidas centrales como soporte de los modelos.
- Folium: Esta librería nos permitirá graficar sobre un sistema de geolocalización, emplear la capa de mapas de calor y georeferenciar el centro de gravedad del modelo.
- Pandas: Es un paquete de Python que proporciona estructuras de datos rápidas, y flexibles, diseñadas para que el trabajo con datos estructurados (tabulares, multidimensionales, potencialmente heterogéneos) y de series de tiempo sea fácil e intuitivo.
- Numpy: Es una librería que nos permitirá efectuar operaciones matriciales en Python.
Para desarrollar estas herramientas, vamos a plantear un caso típico de localización de una instalación (por ejemplo un depósito) a partir de la consideración de otras instalaciones (nodos de demanda, por ejemplo).
Caso de aplicación
La empresa Bio-Food está desarrollando un nuevo modelo de negocio en la ciudad de Cali, Colombia. Este consiste en abastecer de comida saludable a la comunidad por medio de Vending Machines (Máquinas expendedoras). En las etapas de formulación de negocio, algo quedó muy claro: El éxito de su modelo consiste en maximizar la disponibilidad de todos los SKUs en cantidades suficientes. Algunas de las referencias son productos perecederos, de manera que consideran que algunos de sus equipos requerirán visitas diarias de reposición, y otros quizá sean surtidos en más de dos ocasiones por día.
La fase inicial de su proyecto consideró la instalación de 13 equipos expendedores en 13 instituciones de educación superior de la ciudad. La logística inicial de su proyecto fue caótica (en fase piloto), algunos equipos funcionaron como sub-bodegas; algunos equipos fueron abastecidos directamente por los proveedores; y consideran la instalación de una bodega principal desde la cual serán abastecidas todas las máquinas que tienen disponibles.
La fase inicial del proyecto arrojó información alrededor del volumen de ventas de cada equipo. Por esta razón, el departamento de logística considera utilizar esta información para efectuar un análisis preliminar y establecer la localización de la bodega principal. A continuación, se relacionan los movimientos de los equipos (media de unidades vendidas por día):
| Máquina | Institución / Lugar | Unidades vendidas |
| 1 | PONTIFICIA UNIVERSIDAD JAVERIANA | 1800 |
| 2 | UNIVERSIDAD DEL VALLE | 1650 |
| 3 | UNIVERSIDAD SAN BUENAVENTURA | 1110 |
| 4 | UNIVERSIDAD ICESI | 1540 |
| 5 | UNIVERSIDAD SANTIAGO DE CALI | 820 |
| 6 | UNIVERSIDAD AUTÓNOMA DE OCCIDENTE | 1020 |
| 7 | UNIVERSIDAD COOPERATIVA DE COLOMBIA | 635 |
| 8 | FUNDACIÓN UNIVERSITARIA SAN MARTÍN | 420 |
| 9 | UNIVERSIDAD LIBRE | 569 |
| 10 | UNIVERSIDAD ANTONIO NARIÑO | 350 |
| 11 | UNICATOLICA – FUNDACION UNIVERSITARIA CATÓLICA LUMEN GENTIUM | 620 |
| 12 | CECEP | 800 |
| 13 | UNIVERSIDAD OBRERA | 250 |
Utilizar el algoritmo de Centro de Gravedad puede servir como referencia para establecer una ubicación tentativa. Sin embargo, las posibilidades de que las coordenadas solución correspondan con un espacio disponible para la ubicación de la instalación son, de verdad, muy pocas.




Por esta razón, es interesante complementar este modelo mediante una capa de visualización de mapas de calor, que consideren la densidad del volumen de ventas de los equipos. De esta manera, puede complementarse el análisis preliminar para la localización de la bodega principal.
Paso 1: Crear el entorno de trabajo en Colaboratory
Lo primero que vamos a hacer consiste en crear un entorno de trabajo en Google Colaboratory, así que vayamos allá: Abrir cuaderno nuevo.
Verán que tienen un lienzo para programar el modelo, así que en este cuaderno podemos ir generando las líneas de código que explicaremos en los pasos siguientes.
Paso 2: Importar las librerías necesarias
Respecto a las librerías, en la introducción del artículo hicimos una descripción de la funcionalidad de cada una, veamos como importarlas en nuestro entorno:
# importar las librerías necesarias
import pandas as pd
import numpy as np
import folium
import statistics
from folium.plugins import HeatMap
import geopy
from geopy.extra.rate_limiter import RateLimiterDe esta manera, tenemos todo lo necesario para empezar a desarrollar nuestro código.
Paso 3: Importar los datos desde Excel
De acuerdo a las necesidades del modelo, podemos desarrollar un código que permita la entrada manual de la información, la captura de los datos desde entornos digitales (Internet, por ejemplo), o podemos, desde luego, alimentar nuestro modelo con información contenida en documentos externos, como es el caso de un archivo de Microsoft Excel.
Esta puede considerarse como una de las ventajas de utilizar Python, su capacidad de integrarse con cualquier fuente de datos. En nuestro caso, toda la información se encuentra contenida en un documento de Excel, el cual presenta el siguiente formato:

En Colaboratory, el siguiente fragmento permitirá cargar un archivo al entorno de ejecución:
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))Al ejecutar este fragmento de código, se abrirá una ventana emergente del explorador que permitirá cargar nuestra base de datos, en nuestro caso el archivo tienen el nombre de vending_machines.xlsx.
La siguiente línea de código permitirá almacenar los datos contenidos en el documento en un Dataframe de nuestro entorno, dentro de la variable data.
#Leer el documento de Excel y almacenar los datos en la variable data
data = pd.read_excel('vending_machines.xlsx')Paso 4: Geocodificar las ubicaciones
Nosotros podemos partir desde la disponibilidad de las coordenadas geográficas de los puntos disponibles (Equipos expendedores). En cuyo caso, geocodificar las ubicaciones no sería necesario. Sin embargo, en nuestro ejemplo, disponemos del nombre de cada institución donde se encuentran ubicados los equipos, así como la ciudad y el país (todos los equipos se encuentran en la misma ciudad); y es necesario geocodificar estos puntos para obtener las coordenadas de latitud y longitud de cada ubicación.
Para lograrlo, utilizaremos el servicio de la librería Geopy (Llamado Nominatim), el cual puede geocodificar nuestras ubicaciones. El servicio funciona de una manera sencilla, recibe una cadena con la información de nuestra ubicación, por ejemplo: ciudad, país, nombre del lugar; y devuelve las coordenadas de latitud y longitud asociadas a cada cadena.
Las siguientes líneas en primer lugar construyen cada cadena por punto (dirección), es decir, concatenan los datos (país, ciudad y nombre del lugar), y luego son geocodificados por Geopy. Veamos:
# fusionamos los datos país, ciudad y lugar en una misma cadena de dirección
geopy.geocoders.options.default_user_agent = "my-application"
data["direccion"] = data["pais"] + ", " + data["ciudad"] + ", " + data["Institución / Lugar"]
#Envíamos los datos a geocodificación
servicio = geopy.Nominatim()
data["coordenadas"] = data["direccion"].apply(RateLimiter(servicio.geocode,min_delay_seconds=1))Pueden apreciar que el código establece que tanto las cadenas con las direcciones concatenadas, como las respuestas en manera de coordenadas, queden dentro del mismo DataFrame donde se encuentran los datos de entrada del modelo. Podemos en cualquier momento confirmar si la geocodificación se ha realizado correctamente, para eso imprimiremos las primeras cinco filas del DataFrame:
data.head()Al ejecutar esta instrucción tenemos la siguiente salida:

Podemos observar cómo bajo la columna ‘direccion’ se han concatenado las columnas ‘pais’, ‘ciudad’ e ‘Institución / Lugar’, tal como lo establecimos previamente. Así mismo, podemos observar la respuesta de Geopy bajo la columna ‘coordenadas’.
Paso 5: Calcular el Centro de Gravedad
El algoritmo de Centro de Gravedad es relativamente sencillo, mucho más cuando se cuenta con los datos debidamente organizados. Las operaciones son sencillas, y en Python, se pueden desarrollar fácilmente mediante productos de matrices.
Ahora bien, la base del algoritmo son las coordenadas. En la respuesta obtenida desde Geopy, que se encuentra contenida en la columna ‘coordenadas’ del DataFrame ‘data’, hay información adicional a las coordenadas necesarias. De hecho el servicio nos devuelve un nombre del lugar, una subregión, puede mostrarnos alguna nomenclatura y claro está, las coordenadas de latitud y longitud. Por tal razón, lo primero que debemos hacer es extraer las coordenadas de latitud y longitud, para eso utilizaremos las siguientes líneas:
# Extraer las coordenadas de latitud y longitud en dos variables separadas (listas)
longs = [coord.longitude for coord in data["coordenadas"]]
lats = [coord.latitude for coord in data["coordenadas"]]Una vez que tengamos las coordenadas de todos los puntos en un par de variables separadas, procedemos a crear nuestro algoritmo de centro de gravedad:
centro_gravedad = {}
centro_gravedad['longs'] = np.dot(longs, data['Unidades vendidas']) / np.sum(data['Unidades vendidas'])
centro_gravedad['lats'] = np.dot(lats, data['Unidades vendidas']) / np.sum(data['Unidades vendidas'])De esta manera, dentro del arreglo ‘centro_gravedad’ deberán quedar las coordenadas solución. Recordemos que este algoritmo utiliza puntos ponderados, en este caso el peso que determina la ponderación está dado por el volumen de ventas de cada equipo (‘Unidades vendidas’).
Podemos ver el resultado, imprimiendo la variable ‘centro_gravedad’:
print(centro_gravedad)
Estas son las coordenadas solución del método de Centro de Gravedad. Sin embargo, recordemos que debemos complementar el desarrollo del modelo mediante un mapa de calor.
Paso 6: Graficar la capa del mapa de calor y el marcador de Centro de Gravedad
En este caso utilizaremos la librería Folium para ambos fines: la capa del mapa de calor, y el marcador de Centro de Gravedad.
Lo primero que haremos será calcular la media de las latitudes y las longitudes para centrar el mapa que obtendremos.
Lo segundo que haremos será crear nuestro mapa, el cual configuraremos con las medidas centrales y un zoom inicial que podemos modificar de acuerdo a nuestras necesidades.
Lo tercero que haremos será crear nuestra capa de mapa de calor, utilizaremos como peso las ‘Unidades vendidas’ para ponderar cada punto del mapa (Vending Machines). Configuramos algunos parámetros a nuestro criterio como la opacidad, la intensidad, el radio de cada punto.
Por último crearemos el marcador de Centro de Gravedad, para ello utilizaremos las coordenadas solución que hallamos en el paso anterior.
# Calcular la media de las latitudes y las longitudes para centrar el mapa
mediaLong = statistics.mean(longs)
mediaLat = statistics.mean(lats)
# Crear un objeto de mapa base Map()
mapa = folium.Map(location=[mediaLat, mediaLong], zoom_start = 12)
# Crear una capa de mapa de calor
mapa_calor = HeatMap( list(zip(lats, longs, data["Unidades vendidas"])),
min_opacity=0.2,
max_val=data["Unidades vendidas"].max(),
radius=50,
blur=50,
max_zoom=1)
#Creamos el marcador de Centro de Gravedad
tooltip = 'Centro de gravedad'
folium.Marker([centro_gravedad['lats'], centro_gravedad['longs']], popup="Centro", tooltip = tooltip).add_to(mapa)
# Adherimos la capa de mapa de calor al mapa principal
mapa_calor.add_to(mapa)
mapaAl ejecutar estas líneas tendremos el siguiente resultado:
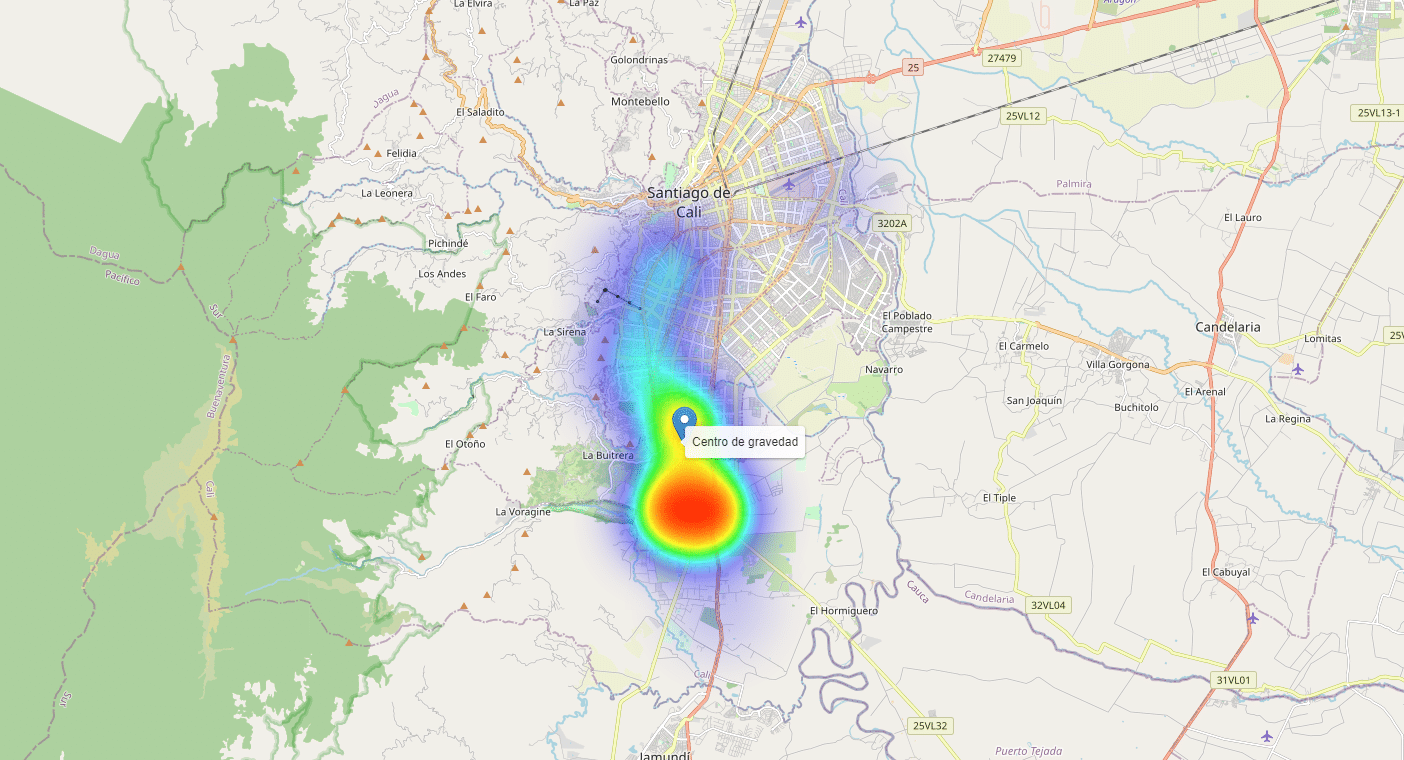
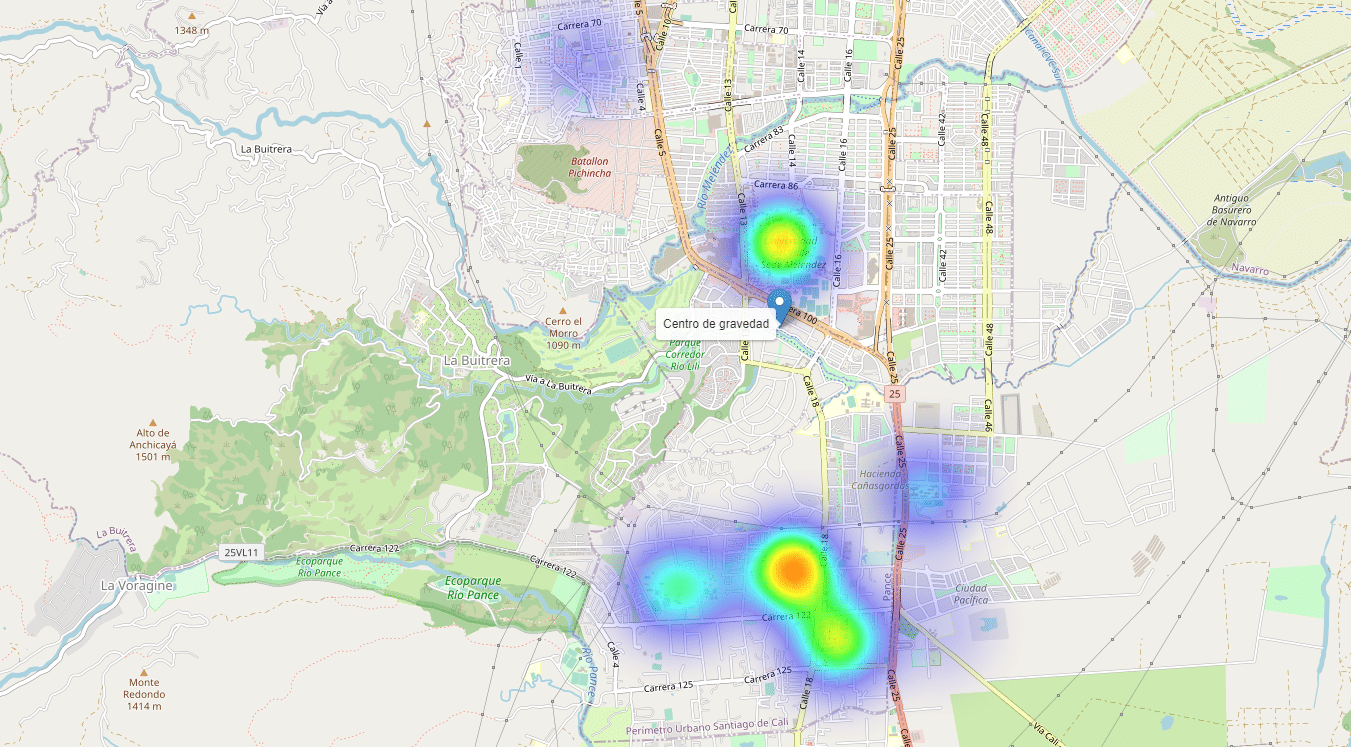
Podemos utilizar el zoom para explorar diversas visualizaciones de densidad:
El código completo de este desarrollo lo puedes encontrar en nuestro cuaderno: Mapas de Calor y Centro de Gravedad.
En este caso, y a diferencia del artículo mapas de calor utilizando Google Maps, empleamos una capa de visualización de densidad de cada punto, y simultáneamente identificamos unas coordenadas solución de una localización de acuerdo al modelo de Centro de Gravedad (Centro de masa). De esta forma, construimos una herramienta un poco más robusta que permite soportar los procesos de análisis preliminar de localización de instalaciones, ambientada en un entorno geográfico real.
Así mismo, en el desarrollo de la herramienta empleamos algunas instrucciones que nos permiten automatizar procesos de georeferenciación, y de uso de datos a partir de fuentes diversas.
El alcance de este modelo se encuentra determinado por la localización de una sola instalación (depósito, almacén, etc.), y en los casos en los que se requiera determinar múltiples localizaciones, el modelo no aplica.
Muchas gracias Ingeniero. Excelente material. Muy claro y ameno para aprender.
Como aporte al caso, yo he venido utilizando OpenStreetMap para recolectar datos con categorías específicas. Por ejemplo, la ubicación de mapas en Bogotá y otros. Herramientas recomendadas:
http://overpass-turbo.eu/ como API para Python en la localización
https://openrouteservice.org/ para el cálculo de matrices de distancias.
Hola Edgar. Gracias por compartir, y por tus comentarios.
Voy a explorar lo que nos compartes. Para cálculo de distancias y tiempos he probado Distance Matrix de Google, con la ventaja de nutrirse de información diaria, y con la posibilidad de acceder a datos de acuerdo a escenarios y medios de transporte
Hola ingeniero, gracias por el material.
Llevé a cabo los pasos indicados, sin embargo me atoré en el paso 4 que es la geocodicicación de las direcciones.
No sé si ha habido algún cambio con respecto a las condiciones iniciales de programación o hay algún otro detalle.
Ojalá me pedas ayudar a resolver el problema.
Gracias.
Hola Jorge. En efecto, un cambio en una de las librerías, pero ya he actualizado el código. Puedes intentar nuevamente.