Localización de varios almacenes mediante agrupación geoespacial
Utilizando Python (Machine Learning)
En un artículo anterior, desarrollamos un modelo capaz de determinar la localización de una instalación (almacén), de acuerdo a un conjunto de ubicaciones existentes (clientes); estas ubicaciones tenían una ponderación determinada (peso, por ejemplo demanda), y basamos nuestro desarrollo en el algoritmo de Centro de Gravedad.
El valor agregado del modelo consistía en la integración de una capa de mapa de calor (para graficar la densidad), un proceso de geocodificación y el uso de un entorno geográfico real. El alcance de este modelo se encuentra determinado por la localización de una sola instalación (depósito, almacén, etc.), y en los casos en los que se requiera determinar múltiples localizaciones, el modelo no aplica.
La pregunta siguiente que nos hacemos es ¿Cómo determinar la localización de múltiples instalaciones? En realidad, hay muchas respuestas para este interrogante, y gran parte de ellas conducen a la agrupación geoespacial (Clustering).
¿Qué es la agrupación geoespacial (Clustering)?
La agrupación geoespacial es un método que se utiliza para asociar un conjunto de objetos espaciales en grupos denominados «clusters«. Los objetos que conforman cada grupo presentan un grado de similitud asociado a un atributo o varios atributos en particular.
El objetivo de la agrupación geoespacial, consiste en determinar una relación entre atributos espaciales (coordenadas, ubicación) y no espaciales (demanda, por ejemplo).
En la literatura encontraremos varios tipos de agrupación geoespacial, cada uno con un enfoque particular, y un campo de aplicación específico; entre los cuales podemos encontrar:
- Agrupación de particiones
- Agrupación jerárquica
- Agrupación Fuzzy
- Agrupación basada en densidad
En nuestro caso, que pretendemos determinar la localización de varias instalaciones, considerando la ponderación y ubicación de los puntos existentes, requerimos de un modelo capaz de relacionar atributos espaciales (coordenadas) y no espaciales (peso de cada nodo). Que nos permita, primero agrupar los puntos dados (ubicaciones), y eventualmente, aplicar un algoritmo de Centro de Gravedad, para determinar localizaciones potenciales.
Para tales efectos, vamos a utilizar la agrupación de particiones, que se caracteriza, entre otras, por:
- Agrupar los puntos espaciales en subconjuntos
- Cada punto agrupado pertenece solo a un subconjunto (clúster)
- Cada subconjunto tiene al menos un punto
Vale la pena destacar que en cuanto a la agrupación de participaciones, en esta categoría encontraremos varios métodos de partición, y nosotros utilizaremos el método K-Means, un algoritmo de aprendizaje automático (Machine Learning) no supervisado. Para ello utilizaremos Python.
Para sintetizar, el objetivo de este artículo será el de emplear un algoritmo de aprendizaje automático capaz de agrupar nuestros nodos en clusters, de acuerdo a atributos espaciales (coordenadas) y no espaciales (ponderación); para luego, utilizar un algoritmo de Centro de Gravedad en cada clúster para determinar la localización de múltiples instalaciones (almacenes, depósitos, etc.).



En el desarrollo de este ejercicio emplearemos:
- Colaboratory: Este es un entorno de programación y ejecución virtual de Python desarrollado por Google. Nos permitirá no tener la necesidad de realizar ninguna instalación en nuestros equipos. Todo lo que desarrollemos lo ejecutaremos en un cuaderno virtual.
- Python: Este será el lenguaje de programación que vamos a utilizar, y advertimos: No es necesario tener conocimientos previos, y el objetivo del artículo no es convertirnos en programadores expertos. Utilizaremos fragmentos de códigos, librerías disponibles, y explicaremos lo necesario para configurar nuestro desarrollo de acuerdo a los objetivos específicos de nuestros modelos.
- SkLearn: Las librerías son a Python, lo que las apps son a un teléfono celular. Esta es quizá una de las características más a tractivas de este lenguaje: Casi que existe una librería para cada necesidad. En este caso, SKLearn, es una librería que integra un conjunto de métodos de aprendizaje automático y minería de datos.
- K-Means: Este es un módulo de SKLearn que contiene el algoritmo de agrupación KMeans, el cual separa muestras en n grupos de varianza igual, minimizando un criterio conocido como inercia o suma de cuadrados dentro del grupo.
- Matplotlib: Es una biblioteca completa para crear visualizaciones estáticas, animadas e interactivas en Python. Nos permitirá visualizar nuestros nodos y nuestras localizaciones solución.
- Pandas: Es un paquete de Python que proporciona estructuras de datos rápidas, y flexibles, diseñadas para que el trabajo con datos estructurados (tabulares, multidimensionales, potencialmente heterogéneos) y de series de tiempo sea fácil e intuitivo.
- Numpy: Es una librería que nos permitirá efectuar operaciones matriciales en Python.
Para desarrollar estas herramientas, vamos a plantear un caso típico de localización de múltiples instalaciones a partir de la consideración de otros nodos (nodos de demanda, por ejemplo).
Caso de aplicación
El Departamento de Desarrollo Sostenible de la ciudad de Cali se encuentra implementando una estrategia piloto de recolección de aceite de cocina usado. Ha articulado este proyecto con una Universidad, la cual desarrolló 4 contenedores inteligentes (BIN’s) para la disposición del bioresiduo.
En investigaciones asociadas, la Universidad ha determinado que el reciclaje del aceite es un problema de densidad; esto quiere decir que es vital la ubicación de los contenedores (cobertura), para así mismo optimizar el proceso de disposición y recolección. El proyecto piloto piensa articular a las instituciones de educación como puntos potenciales de recolección. Por medio de las instituciones piensan socializar el programa con la comunidad. El primer reto del proyecto consiste en determinar la ubicación de los contenedores inteligentes (4 unidades). La información relacionada con las instituciones de educación que hacen parte del programa (ubicación geográfica / población estudiantil), se detalla a continuación:
| Nodo | Lugar (Colegios) | Latitud | Longitud | Peso |
| 0 | Comfandi San Nicolás | 3,453591118 | -76,52254886 | 1494 |
| 1 | Mayor de Santiago de Cali | 3,451577758 | -76,51023216 | 908 |
| 2 | Municipal Comfandi | 3,448107915 | -76,51074714 | 697 |
| 3 | Internado San Carlos | 3,446994135 | -76,51525325 | 1714 |
| 4 | León de Greiff | 3,447979402 | -76,49993247 | 1731 |
| 5 | Nuestra Señora de la Anunciación | 3,445152112 | -76,49641342 | 2297 |
| 6 | Fernando de Aragón | 3,437355603 | -76,51383704 | 1265 |
| 7 | Casa Evangélica | 3,437955337 | -76,52299947 | 1658 |
| 8 | San Alberto Magno | 3,433028941 | -76,52707643 | 604 |
| 9 | Santa María Goretty | 3,433414486 | -76,50720662 | 416 |
| 10 | San Alberto Magno | 3,433157456 | -76,5267331 | 1584 |
| 11 | San Ignacio de Loyola | 3,431786629 | -76,51733464 | 2350 |
| 12 | Nuestro Futuro | 3,430629992 | -76,50360174 | 964 |
| 13 | Sabio Caldas | 3,429087807 | -76,51660508 | 329 |
| 14 | CREAD | 3,425060978 | -76,51488847 | 774 |
| 15 | Licomtec | 3,416664559 | -76,51673383 | 1818 |
| 16 | Nuestra Señora De La Providencia | 3,419534772 | -76,49591989 | 1530 |
| 17 | Real Suizo | 3,415208029 | -76,49323768 | 2106 |
| 18 | Nuevo Edén | 3,415722099 | -76,53383559 | 330 |
| 19 | Católico | 3,413066071 | -76,53984374 | 976 |
| 20 | Santa María Stella | 3,427031556 | -76,55134505 | 1975 |
| 21 | Santa Isabel | 3,40805355 | -76,50817223 | 936 |
| 22 | Compartir | 3,431957663 | -76,47495575 | 1563 |
| 23 | Lancaster | 3,400770816 | -76,55177421 | 1219 |
| 24 | Parroquial Divino Salvador | 3,397086588 | -76,54259033 | 1954 |
| 25 | Reyes Católicos | 3,393316667 | -76,53735466 | 399 |
| 26 | Liceo Anglo del Valle | 3,387318719 | -76,51975937 | 1741 |
| 27 | Laurence | 3,383420238 | -76,52078934 | 1111 |
| 28 | Los Almendros | 3,381278208 | -76,52023144 | 1826 |
| 29 | Bautista | 3,37720834 | -76,52327843 | 1772 |
| 30 | Lacordaire | 3,378150837 | -76,54460736 | 1965 |
| 31 | General José María Córdoba | 3,393573314 | -76,54932805 | 841 |
| 32 | El Hogar | 3,390745864 | -76,5503151 | 770 |
| 33 | Americano | 3,379093255 | -76,54688187 | 650 |
| 34 | Santa Filomena | 3,401969935 | -76,51345082 | 1401 |
| 35 | Tomás Vasconi | 3,403040928 | -76,5173132 | 1474 |
| 36 | República del Salvador | 3,404454636 | -76,52143308 | 1926 |
| 37 | Los Andes | 3,429601077 | -76,53761216 | 1566 |
| 38 | Villacolombia | 3,445493943 | -76,50169202 | 2354 |
| 39 | Las Américas | 3,449220822 | -76,50594064 | 2043 |
| 40 | SantaFe | 3,442238267 | -76,50988885 | 2333 |
| 41 | Evaristo García | 3,440781776 | -76,51752778 | 696 |
| 42 | Alfredo Vasquez Cobo | 3,435598366 | -76,5164549 | 1073 |
| 43 | Ciudad de Cali | 3,431143181 | -76,51272126 | 1275 |
| 44 | INEM | 3,482761991 | -76,49976083 | 1485 |
| 45 | Olaya Herrera | 3,478178519 | -76,51280709 | 1470 |
| 46 | Guillermo Valencia | 3,47449459 | -76,5136654 | 1248 |
| 47 | José Ignacio Rengifo | 3,471624543 | -76,5136654 | 2160 |
| 48 | Santo Tomás | 3,45830227 | -76,5164549 | 1776 |
| 49 | La Merced | 3,46271449 | -76,5024645 | 706 |
| 50 | Pedro Antonio Molina | 3,482804827 | -76,48761579 | 2369 |
| 51 | Santa Librada | 3,46228612 | -76,52302095 | 2498 |
| 52 | República de Israel | 3,463656904 | -76,51053258 | 1510 |
| 53 | San Vicente Paul | 3,466227117 | -76,50950261 | 2330 |
| 54 | Manuel María Mallarino | 3,456760129 | -76,48851701 | 1464 |
| 55 | Sebastían de Belalcazar | 3,460229941 | -76,48521253 | 628 |
| 56 | Liceo Departamental | 3,423860462 | -76,5385563 | 364 |
| 57 | Libardo Madrid | 3,422061154 | -76,54383489 | 2439 |
| 58 | Metropolitano Santa Anita | 3,401691038 | -76,54218265 | 1815 |
| 59 | San José | 3,396935816 | -76,55031511 | 2230 |
Para tales efectos, desarrollaremos un modelo que apoye el análisis preliminar y la localización de los múltiples contenedores. También, que tenga la capacidad de predecir el grupo (clúster) al que pertenecería un nodo nuevo.
Paso 1: Crear el entorno de trabajo en Colaboratory
Lo primero que vamos a hacer consiste en crear un entorno de trabajo en Google Colaboratory, así que vayamos allá: Abrir cuaderno nuevo.
Verán que tienen un lienzo para programar el modelo, así que en este cuaderno podemos ir generando las líneas de código que explicaremos en los pasos siguientes.
Paso 2: Importar las librerías necesarias
Respecto a las librerías, en la introducción del artículo hicimos una descripción de la funcionalidad de cada una, veamos como importarlas en nuestro entorno:
#Importar las librerías necesarias
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeansDe esta manera, tenemos todo lo necesario para empezar a desarrollar nuestro código.
Paso 3: Importar los datos desde Excel
De acuerdo a las necesidades del modelo, podemos desarrollar un código que permita la entrada manual de la información, la captura de los datos desde entornos digitales (Internet, por ejemplo), o podemos, desde luego, alimentar nuestro modelo con información contenida en documentos externos, como es el caso de un archivo de Microsoft Excel.
Esta puede considerarse como una de las ventajas de utilizar Python, su capacidad de integrarse con cualquier fuente de datos. En nuestro caso, toda la información se encuentra contenida en un documento de Excel, el cual presenta el siguiente formato:
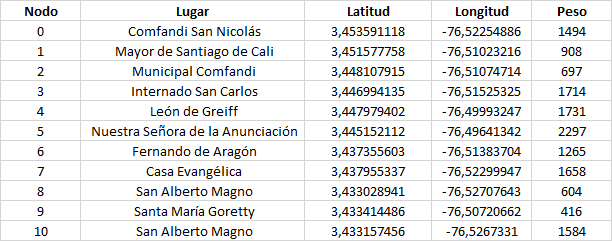
Ya veremos cómo, parte de estos datos son prescindibles y otros indispensables.
En Colaboratory, el siguiente fragmento permitirá cargar un archivo al entorno de ejecución:
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))Al ejecutar este fragmento de código, se abrirá una ventana emergente del explorador que permitirá cargar nuestra base de datos, en nuestro caso el archivo tienen el nombre de cluster.xlsx.
La siguiente línea de código permitirá almacenar los datos contenidos en el documento en un Dataframe de nuestro entorno, dentro de la variable data.
#Leer el documento de Excel y almacenar los datos en la variable data
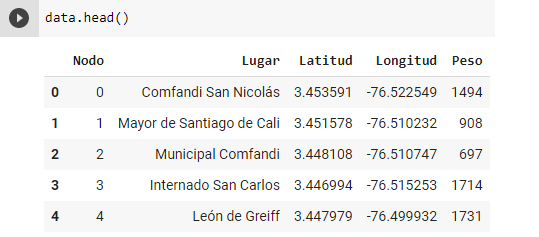
data = pd.read_excel('cluster.xlsx')Podemos en cualquier momento confirmar si la carga de los datos se ha realizado correctamente, para eso imprimiremos las primeras cinco filas del DataFrame:
data.head()Al ejecutar esta instrucción tenemos la siguiente salida:
Paso 4: Graficar los puntos dados iniciales (Nodos)
Nuestros puntos iniciales, o las ubicaciones de partida son las instituciones de educación que nos otorga el planteamiento del problema.
Para graficar estos puntos utilizamos el sistema de coordenadas disponible: Latitud y Longitud. Así entonces, debemos extraer estos datos de la hoja de cálculo (DataFrame) que hemos importado al modelo; convertir estas coordenadas en una matriz bidimensional (Latitud y Longitud) y graficar los puntos:
#Graficar los nodos dados (ubicaciones)
Lat= data['Latitud']
Lon = data['Longitud']
Peso = data['Peso']
X = []
for i in range(len(data['Latitud'])):
X.append(Lat[i])
X.append(Lon[i])
X = np.array(X)
X = X.reshape(-1, 2,)
plt.scatter(Lat, Lon)
plt.show()Al ejecutar este fragmento de código, tendremos:
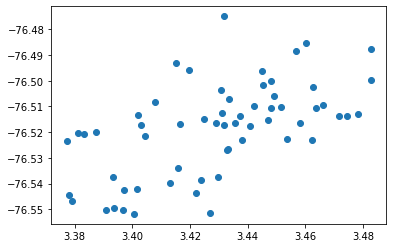
Podemos apreciar cómo se encuentran dispersos los nodos iniciales, formando parte un mismo conjunto que es la población. Las coordenadas son latitud y longitud. Los nodos son, una vez más recordamos, las instituciones educativas, de acuerdo al caso de estudio.
Paso 5: Agrupar los nodos geoespacialmente mediante Machine Learning
Cuando mencionamos Machine Learning, a menudo la primera consideración que tenemos es de complejidad. Pues bien, muchos de los algoritmos que hemos utilizado durante décadas son en realidad de aprendizaje automático, como por ejemplo la regresión lineal. El algoritmo de K-Means que emplearemos de forma automatizada mediante Python, utiliza centroides que minimizan la inercia, o el criterio de suma de cuadrados de cada clúster:
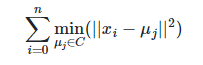
Me pareció conveniente explicar un poco la teoría, pero vayamos a la práctica. Toda vez que tenemos los nodos del modelo, lo siguiente que debemos indicar es la cantidad de agrupaciones que queremos (clúster). Ya que el problema plantea la disposición de 4 contenedores, vamos a dividir la población de nodos en 4 conjuntos.
Luego, correremos el algoritmo K-Means, veamos cómo:
#Ejecutar el algoritmo KMeans
clusters = 4
KMean = KMeans(n_clusters=clusters)
KMean_g = KMean.fit_predict(X)
KMean.fit(X)Lo siguiente que haremos será establecer los centroides de cada clúster, es decir, la ubicación de nuestros contendores. En primer lugar, el modelo nos dará las coordenadas. Utilizaremos la siguiente línea de código:
#Determinar los centroides de cada clúster
KMean.cluster_centers_Al ejecutarla tendremos:
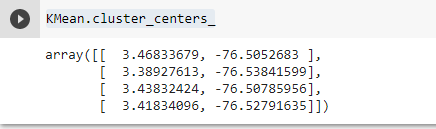
Estas son las coordenadas que indican el centro de cada uno de nuestros grupos de nodos. Y teóricamente ahí deberíamos disponer nuestros contenedores.
Paso 6: Graficar los clusters y los centroides (Localizaciones múltiples)
El siguiente paso consiste en graficar todas las coordenadas que ya tenemos: tantos los nodos iniciales, como los los centroides, o las localizaciones solución. Veamos cómo:
#Graficar todas las coordenadas (Puntos y centroides)
plt.scatter(X[:,0], X[:,1], c=KMean_g) #Puntos iniciales
#Centroides
plt.scatter(KMean.cluster_centers_[0][0], KMean.cluster_centers_[0][1], s=50, c='r')
plt.scatter(KMean.cluster_centers_[1][0], KMean.cluster_centers_[1][1], s=50, c='r')
plt.scatter(KMean.cluster_centers_[2][0], KMean.cluster_centers_[2][1], s=50, c='r')
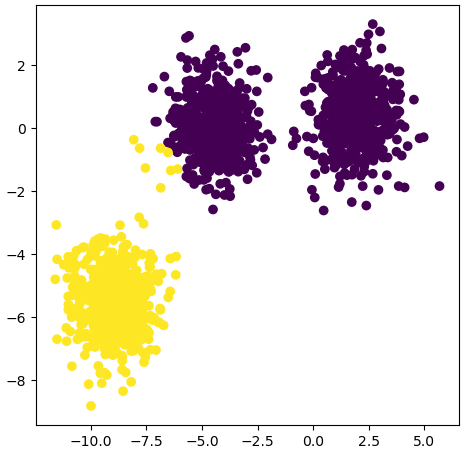
plt.scatter(KMean.cluster_centers_[3][0], KMean.cluster_centers_[3][1], s=50, c='r')Al ejecutar el fragmento tendremos:
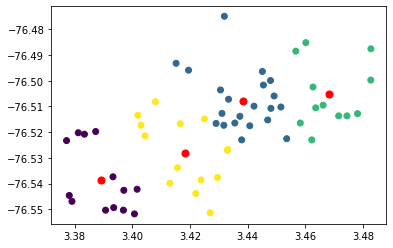
Vemos cómo se han efectuado las agrupaciones de los nodos (colores), y los marcadores rojos indican los centroides. Este debería ser el final de nuestro desarrollo, sin embargo, no sé si lo han notado, siempre hemos hablado de centroides, nunca de centros de gravedad o centros de masa. Bien, no sé si también han identificado que en ningún momento hemos considerado el peso de cada nodo, en este caso la población estudiantil de cada institución.
¿Esto qué implica? Implica que hemos desarrollado un modelo que tiene exclusivamente consideraciones espaciales. De hecho, visualmente puede observarse cómo, básicamente los centroides se ubican en lo que podría considerarse el medio de cada clúster, sin ninguna consideración adicional aparente, por lo menos a la vista.
Pues bien, vamos a solucionarlo, para ello debemos retocar algunos de los pasos anteriores:
Paso 5 (Recargado): Agrupar los nodos geoespacialmente mediante Machine Learning (Considerando atributos espaciales y no espaciales)
Dentro de nuestro marco de datos (DataFrame) tenemos la información relacionada al peso de cada nodo (Población estudiantil). Pues bien, vamos a considerarla al ejecutar el algoritmo K-Means.
#Ejecutar el algoritmo KMeans (Considerando el peso de los nodos)
clusters = 4
KMean = KMeans(n_clusters=clusters)
KMean_g = KMean.fit_predict(X)
KMean.fit(X, sample_weight=Peso)Lo siguiente que haremos será establecer los centroides de cada clúster, que ahora sí serán Centros de Gravedad; es decir, la ubicación de nuestros contendores. En primer lugar, el modelo nos dará las coordenadas. Utilizaremos la siguiente línea de código:
#Determinar los centroides de cada clúster
KMean.cluster_centers_Al ejecutarla tendremos:
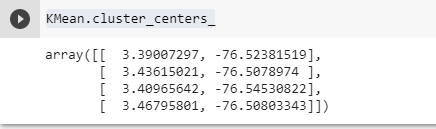
Los centroides han cambiado, ahora son centros de gravedad afectados por el peso de cada nodo. Es posible que incluso haya cambiado la agrupación de los nodos (composición de los clusters).
Paso 6 (Recargado): Graficar los clusters y los Centros de Gravedad (Localizaciones múltiples)
El siguiente paso consiste en graficar todas las coordenadas que ya tenemos: tantos los nodos iniciales, como los los Centros de Gravedad, o las localizaciones solución. Veamos cómo:
#Graficar todas las coordenadas (Puntos y centroides)
plt.scatter(X[:,0], X[:,1], c=KMean_g) #Puntos iniciales
#Centroides
plt.scatter(KMean.cluster_centers_[0][0], KMean.cluster_centers_[0][1], s=50, c='r')
plt.scatter(KMean.cluster_centers_[1][0], KMean.cluster_centers_[1][1], s=50, c='r')
plt.scatter(KMean.cluster_centers_[2][0], KMean.cluster_centers_[2][1], s=50, c='r')
plt.scatter(KMean.cluster_centers_[3][0], KMean.cluster_centers_[3][1], s=50, c='r')Al ejecutar el fragmento tendremos:
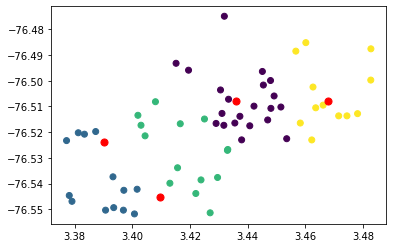
El resultado respecto a los centroides es diferente. La consideración de un atributo no espacial, en este caso el peso de cada nodo (población estudiantil de cada institución educativa), ha incidido en la ubicación propuesta de las localizaciones solución. Y este debería ser el final de nuestro modelo.
Hemos logrado agrupar nuestros puntos iniciales en clusters, y luego hemos determinado los Centros de Gravedad de cada uno de los clusters.
Por último, veamos una característica de la librería K-Means Análisis predictivo de nodos en clusters, es decir, de acuerdo a unas coordenadas dadas, podemos estimar el grupo al que pertenecerá un nuevo nodo.
Paso 7: Predicción de clusters
En primer lugar ejecutaremos una línea que nos permite identificar a cada nodo dentro de un grupo. Ya que tenemos 4 grupos, estos se identificarán de la siguiente manera: 0, 1, 2, 3.
KMean.labels_Al ejecutar esta línea tendremos:

Vemos como cada una de las 60 instituciones educativas (nodos), tienen un identificador de grupo dentro del modelo.
Ahor, dadas las coordenadas de un nuevo nodo, podemos predecir el grupo al cual pertenecerá:
sample_test=np.array([-3.433,-76.22])
second_test=sample_test.reshape(1, -1)
KMean.predict(second_test)Al ejecutar este fragmento tendremos:
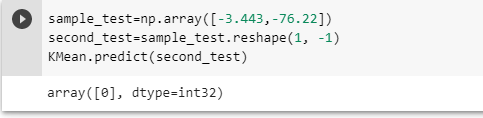
Es decir, el algoritmo predice que de acuerdo a las coordenada dadas, el nuevo nodo formaría parte del clúster 0.
Pudimos observar cómo varía el resultado dependiendo de la consideración de atributos netamente geoespaciales, y de atributos no espaciales, como la ponderación de cada nodo.
Integración con mapas de calor y entornos geográficos reales
Uno de los puntos negativos del modelo que acabamos de desarrollar es quizá que no nos permite visualizar gráficamente la densidad de los puntos. Si observamos las gráficas, todos los puntos parecen tener el mismo tamaño, y si bien esta no es una consideración para el funcionamiento del algoritmo; en el análisis preliminar quisiéramos tener esta herramienta. Otra consideración adicional sería la posibilidad de graficar todos nuestros puntos, y los centros de gravedad de cada (clúster) en un entorno geográfico real.
Pues bien, una de las ventajas fundamentales de Python consiste en que podemos integrar distintos desarrollos en nuestros modelos, tal es el caso del desarrollo que efectúanos en un artículo anterior (Mapas de calor y Entornos geográficos reales); de tal manera que podamos complementar nuestro modelo.
No vamos a profundizar en la librerías, ni en la definición de las variables, para eso recomendamos leer el artículo. Veamos entonces, como complementamos este modelo:
import folium
import statistics
from folium.plugins import HeatMap
mediaLong = statistics.mean(Lon)
mediaLat = statistics.mean(Lat)
# Crear un objeto de mapa base Map()
mapa = folium.Map(location=[mediaLat, mediaLong], zoom_start = 13)
# Crear una capa de mapa de calor
mapa_calor = HeatMap( list(zip(Lat, Lon, data["Peso"])),
min_opacity=0.2,
max_val=data["Peso"].max(),
radius=50,
blur=50,
max_zoom=1)
#Creamos el marcador de Centro de Gravedad
tooltip = 'Centro de gravedad'
folium.Marker([KMean.cluster_centers_[0][0], KMean.cluster_centers_[0][1]], popup="Centro", tooltip = tooltip).add_to(mapa)
folium.Marker([KMean.cluster_centers_[1][0], KMean.cluster_centers_[1][1]], popup="Centro", tooltip = tooltip).add_to(mapa)
folium.Marker([KMean.cluster_centers_[2][0], KMean.cluster_centers_[2][1]], popup="Centro", tooltip = tooltip).add_to(mapa)
folium.Marker([KMean.cluster_centers_[3][0], KMean.cluster_centers_[3][1]], popup="Centro", tooltip = tooltip).add_to(mapa)
# Adherimos la capa de mapa de calor al mapa principal
mapa_calor.add_to(mapa)
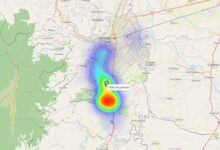
mapaAl ejecutar este fragmento tendremos el siguiente resultado:
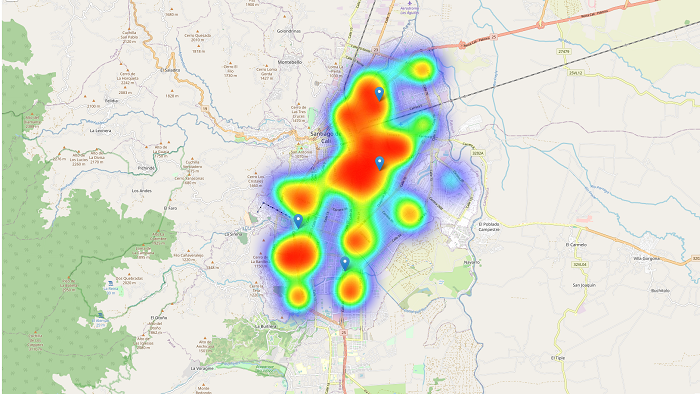
Ahora tenemos un modelo capaz de agrupar nuestros nodos en clusters de acuerdo a atributos geoespaciales; capaz de determinar los centros de gravedad de cada cluster de acuerdo a atributos no espaciales (en nuestro caso la población de los nodos); capaz de complementarse con una capa de visualización de mapa de calor que nos permite apreciar la densidad y todo esto puede visualizarse en un entorno geográfico real.
Consideraciones finales
Ya lo expresamos anteriormente, la base del algoritmo K-Means es la consideración y minimización de la inercia, y en espacios de muy altas dimensiones, las distancias suelen inflarse, ya que esta no es una medida normalizada.
Sin embargo, para los efectos que hemos empleado, el algoritmo suele arrojar resultados satisfactorios.
El código completo de este desarrollo lo puedes encontrar en nuestro cuaderno: Localización de varias instalaciones mediante agrupación geoespacial y Centro de Gravedad (Python).